Spark Python API
基础类型
数据类型
DataType是具体数据类型的基类。
| 类型 | Python类型 | 说明 |
|---|---|---|
BooleanType | bool | |
ByteType | ||
IntegerType | int | ShortType/LongType |
DoubleType/FloatType | float | |
DecimalType() | precision,scale参数控制精度; | |
StringType | str | |
DateType | dt.date | |
TimestampType | dt.datetime | |
NullType | None | |
BinaryType | ||
ArrayType(EType) | List[Type] | nullable=True |
MapType(KType,VType) | dict | 必须声明确定的key和value类型(命名元组)。nullable=True |
StructType([fields]) | dict | StructType包含固定字段;而MapType可以有任意数量的key-value。 |
StructField(name,DType) | nullable=True |
Data Types - Spark 3.2.0 Documentation (apache.org)
数据结构
底层API
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("AppName").setMaster(master).set(...)
sc = SparkContext(conf=conf)
master表示集群的URL,或者local[k]。
交互式环境(PySparkShell)中有一个默认的
SparkContext对象sc。
输入
文件
lines = sc.textFile("examples/src/main/resources/people.txt")
默认文件传输协议为
file://;使用Spark-on-Yarn时,默认的文件传输协议为hdfs://,即文件应该存储在HDFS集群上。如果要在Client模式下使用主程序所在节点的文件,显式指定协议为file://。省略文件传输协议,且路径非
/开头,则表示使用相对路径。
local:/不是有效的文件传输协议(仅适用于Spark集群自身分发依赖库)。
变换
map()
输出
first()
Spark SQL
Spark会话
from pyspark.sql import SparkSession
spark=SparkSession\
.builder\
.master("yarn")
.appName("PythonApp")\
.config("hive.metastore.uris", "thrift://hadoop-master:9083")\
.enableHiveSupport()\
.getOrCreate()
# 如果能定位SPARK_HOME下的配置文件,则可获得相应配置,否则需要通过代码指定
spark.sparkContext.setLogLevel('WARN') # set log level to WARN after then
数据类型
输入数据以pyspark.sql.DataFrame表示。DataFrame相当于是基于Row组织的RDD,可与RDD相互转换。
Spark DataFrame
spark.createDataFrame(data[,schema][,samplingRatio],verifySchema=True)
基于Row序列(本地或分布式RDD类型)创建,
data = [Row(a=1, b=2., c='string1', d=date(2000, 1, 1)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1))]
# data = spark.sparkContext.parallelize(data) -> RDD
df = spark.createDataFrame(data) # 自动推测数据类型
基于Python序列(本地或分布式RDD类型)创建,由于序列没有列名信息,需要指定schema。
data = [(1, 2., 'string1', date(2000, 1, 1)),
(2, 3., 'string2', date(2000, 2, 1)),
(4, 5., 'string3', date(2000, 3, 1))]
# data = spark.sparkContext.parallelize(data) -> RDD
df = spark.createDataFrame(data, schema='a long, b double, c string, d date')
Spark Row类型
Row表示Spark DataFrame中的一行数据,可以使用字典、元组的方式访问其元素,也可以将元素名称作为成员名来访问该元素(类似于命名空间成员的访问方式)。
from pyspark.sql import Row
row = Row(name="Alice", age=11)
'name' in row
row.age, row['name'], row[1]
Person = Row("name", "age")
Person("Alice", 11) # Row(name='Alice', age=11)
数据格式声明
schema可以以字符串形式简单描述(类型可省略,根据数值采样自动推测)或使用StructType完整描述。
schema = StructType([StructField("a", StringType(), True),
StructField("b", DoubleType(), False),
StructField("c", StringType(), True),
StructField("d", DateType(), False)])
还可以基于pandas.DataFrame创建。由于pandas.DataFrame已知数据类型,无需指定Schema。
pd.DataFrame(pandas_df)
读取文件
reader:DataFrameReader = spark.read:获取读取接口,可通过以下方式对该接口进行配置:reader.format(<FORMAT>) ->reader.<FORMAT>:支持的文件格式包括Text、CSV、Parquet、OCR、JSON等。
df = spark.read.json(FILE_PATH)
df = spark.read.format("JSON").load(FILE_PATH)
reader.option(key, value)/options(**options):设置输入选项;
csv读取参数
-
schema:StructType或文本col0 INT, col1 DOUBLE;header=False;inferSchema=False:推断数据格式,需要读取两次数据;samplingRatio=1.0:推断数据格式所需读取的记录比例;enforceSchema=True:默认强制应用指定的或推断的数据格式被数据源所有文件,CSV文件中的头部被忽略;反之,仅验证CSV文件的头部字段(推荐禁用该选项以避免意外错误)。maxColumns=20480:限制读取的列数;multiLine=False:数据记录跨行;
csv不支持仅读取部分数据,可在读取后执行limit()方法返回部分数据 -
文本编码:
encoding='UTF-8'; -
特殊字符:
sep=',';quote='"':用于包含分隔符的字段;escape='\':用于转义已经使用引号的字段中的引号,即\";charToEscapeQuoteEscape='\';用于转义引号字段中的转义字符,即\\;comment=None(数据中的注释行开头字符);ignoreLeadingWhiteSpace/ignoreTrailingWhiteSpace=False:忽略空白;
-
特殊值:
nullValue='':文件中的缺失值形式;emptyValue='""':文件中空字符串的形式;nanValue='NaN':文件中无效数值的表示形式;positiveInf/negativeInf='Inf':文件中无穷大的表示形式;
-
数值格式:
dateFormat='yyyy-MM-dd':文件中日期表示形式;timestampFormat="yyyy-MM-dd'T'HH:mm:ss.SSSXXX":文件中时间表示形式;maxCharsPerColumn=-1:限制每个字段读取字符数量(默认无限制);
-
错误处理:
mode='PERMISSIVE':发现坏记录将其存储在名为columnNameOfCorruptRecord的列(需要用户在数据格式中设置该列,否则丢弃该列),并将其他列设置为null;当记录字段比数据格式的列少,则缺少的列设置为null;反之,丢弃多余的列。DROPMALFORMED忽略整条坏记录。FAILFAST直接抛出异常。columnNameOfCorruptRecord=spark.sql.columnNameOfCorruptRecord:
Hive
df = spark.sql("select * from pokes limit 10")
Hive数据源格式
CSV文件:为了保证Spark能正确推测Hive数据的数据类型,Hive数据源的文件存储中不要包含表头(Spark不识别Hive的表格选项skip.header.line.count),否则Spark将表头视为数据,由于表头为字符串类型,导致自动推导数据类型失败。对于具有表头的数据文件,可直接存储在HDFS上,并通过Spark提供的CSV文件读取接口读取数据。
数据表视图
df.createOrReplaceTempView("people") # createTempView(name)
df = spark.sql("SELECT * FROM people")
df.createGlobalTempView("people") # createOrReplaceGlobalTempView()
df = spark.sql("SELECT * FROM global_temp.people")
df = spark.table('global_temp.people')
DataFrame API
df.cache():持久化数据(MEMORY_AND_DISK);df.persist([storageLevel])设置持久化存储等级;
df.unpersist([blocking]):释放持久化存储资源;
df.coalesce(numPartitions):重新分片;
df.withColumnRenamed(existing, new):重命名列;对于为暂未计算的抽象列Column调用其alias方法修改随后返回的数据的列名。
df.columns:返回列名组成的列表。
df.dtypes->List[(name,type)]
df.schema->StructType
df.isStreaming:该数据集是否是流数据;
df.rdd->RDD(List[Row])
df.toJSON(use_unicode=True)->RDD(List[str])
变换
-
df.select(col:Column,...):从DataFrame选择列并执行变换,select执行的操作类似于map。可以提供序列类型或可变长参数列表作为参数。Column类用于表示==基于列的变换过程的声明式对象==,包括以下声明方式:-
'col_name'|col/column(col_name)|df['col_name']|df.col_name:使用列名读取该列不做其他变换;仅提供列名默认引用当前查询的数据集的列;from pyspark.sql.functions import col,column # col<->column可使用
df.columns[i:j]选择数据的一个分片。对于结构数据字段可通过路径对象来返回嵌套字段值:
df.select("name.firstname","name.lastname").show(truncate=False) -
df.col_name+1:基于列的数值运算、逻辑运算(+,-,*,/...)等;参与运算的数值不能是
numpy类型的数值,否则会出错:'numpy.int32' object has no attribute '_get_object_id';应该将此类型转换为兼容的Python内置类型。 -
df.col_name.func(),df['col_name'].func()或col('col_name').func():使用列名调用内置的变换方法; -
sqlfunc(col('col_name'))或sqlfunc(df['col_name']):使用SQL函数库或或自定义变换函数。SQL函数可能不接受字符串列名。from pyspark.sql.functions import sqlfunc; # 从内置SQL函数库导入变换方法 pysaprk.sql.functions import udf; # 通过udf,用户可自定义变换函数 -
expr("EXPR"):由于表达式文本在运行时构造,这种方式==可动态生成查询语句==;from pyspark.sql.functions import expr df.select(expr('a*2+1'))
-
-
df.selectExpr(*expr):使用表达式代文本替df.select()的列声明(df.select('col_name')的扩展,等效于df.select(expr("EXPR"))),这种方式无法通过列声明对象调用内置方法(如列重命名)。df.selectExpr("age * 2", "abs(age)") -
SQL查询语句:通过构造数据表视图并利用
spark.sql(...)方法传入包含SQL变换方法的原生SQL查询语句进行数据变换。df.createOrReplaceTempView('data') spark.sql('SELECT a, FUNC(a) FROM data').show() -
df.transform(func):func可包含一系列select变换; -
条件变换:
when相当于是一个条件选择函数的简化形式。from pysaprk.sql.functions import when df.select(when(df.col==1,df.col+1).otherwise(0).alias("result"))
通过列声明调用变换方法
Column.cast/astype(TYPE):列数据类型变换,TYPE可以是文本类型描述或DataType的子类对象。
Column.alias/name:修改列名,默认列名为该列的变换表达式;
Column.asc/asc_nulls_first/asc_nulls_last/desc/desc_nulls_first/desc_nulls_last(col):参考对应的SQL函数;
Column.bitwiseAND/bitwiseOR/bitwiseXOR
Column.between(lower,upper):判断列值是否在上下界之间;
Column.startswith/endswith(other)
Column.contains(other)
Column.isin(*cols):当前列的值是否在其他列中;
Column.dropFields(*fields)/getField(name)/withField(name,value):提取/丢弃/修改StructType字段;
Column.getItem(idx_or_key):从序列或字典中提取元素或字段;
Column.eqNullSafe(other):NaN = NaN returns true.
Column.isNull/isNotNull()
Column.like/rlike(other):模糊匹配/正则匹配;
Column.substr(startPos,length):获取子串(functions.substring);
SQL变换函数
Sspark定义了大量内置的变换函数以及自定变换函数的接口。
import pyspark.sql.functions as sqlfunc
自定义变换函数
from pyspark.sql.functions import udf
@udf(returnType=ArrayType(StringType()))
def str_2_array(x: str):
if x is None: return []
elif x.startswith('[') and x.endswith(']'): return eval(x)
else: return [x]
df.select(str_2_array(df.a)).show()
Pandas变换函数
from pyspark.sql.functions import pandas_udf
@pandas_udf(returnType='long', functionType=None)
def pandas_plus_one(series: pd.Series) -> pd.Series:
return series+1
df.select(pandas_plus_one(df.a)).show()
def filter_func(iterator):
for pdf in iterator: # iterator over pandas DataFrames
yield pdf[pdf.id == 1] # return iterator of pandas DataFrames
df.mapInPandas(filter_func, df.schema).show() # [3.0]
def plus_mean(pandas_df):
return pandas_df.assign(v1=pandas_df.v1 - pandas_df.v1.mean())
df.applyInPandas(plus_mean, schema=df.schema).show()
SparkML变换方法
SparkML提供了基于数值特征的变换方法fit/transoform(),==支持拟合变换过程中的参数;相比之下,基于select()和SQL变换函数,需要自己实现参数拟合的方法==。此外,SparkML提供的变换类,支持同时处理多个列;SQL变换函数的输入为一列,需要自己实现多列处理逻辑并记录对应参数。
SparkML的变换方法的输入要求==将每一行数据参与变换的特征列拼接为向量Vector==(SQL函数库中的array函数实现的拼接与变换方法的输入类型不一致),可以使用VectorAssembler实现此变换。
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=["x", "y", "z"], outputCol="features")
x = assembler.transform(x)
some_transformer = SomeTransformer(*,inputCol='features',outputCol='_features')
model = some_transformer.fit(x) # -> SomeTransformerModel
x = model.transform(x).drop('features').withColumnRenamed('_features', 'features')
变换后的数据包含原有数据列,以及变换后新增的features列(DenseVector)。为了方便后续分别处理各特征列的数据,需要将features[拆分为多列](# 将字典或序列转换为多列)。
@udf(returnType=ArrayType(DoubleType())) # from pyspark.sql.functions import udf
def vector_2_array(x: DenseVector):
return [ float(i) for i in x ]
y:SparkColumn = vector_2_array(x['features']).alias('features')
y = {col: y.getItem(i).alias(col) for i, col in enumerate(_columns)}
x = x.select(*x.columns, *y.columns) # 此处需要处理变换后的重名列(drop or rename)
Spark 3.0
pyspark.ml模块自带vector_to_array()方法。
列变换
内置变换方法来自pyspark.sql.functions(SQL函数)和pyspark.ml.feature(变换类)等模块。
broadcast(df)
bucket(numBuckets, col)
coalesce(*cols):返回第一个不为null的列;
生成列
input_file_name():获取当前任务的文件名;
current_date/current_timestamp():返回当前日期,同一个查询中的调用返回相同值。
lit(VALUE):创建常量列;
monotonically_increasing_id():
rand(seed=None)/randn([seed]):生成[0,1)区间均匀分布/标准正态分布随机数;
sequence(col_start,col_stop[,col_step]):生成等差数列数组,输入参数为列名或常量列(lit);
spark_partition_id():
无效值处理
isnan/isnull(col):判断值是否为NaN/null;
nanvl(col1, col2):如果col1!=NaN,返回col1;否则返回col2;
df.fillna(value[,subset])
数值计算函数
abs/exp/expm1/sqrt/cbrt/log/log10/log1p/log2(col)/pow(x,y):cbrt三次方根,expm1->$e^x-1$;
greatest/least(*cols):返回多个列元素中的最大/小值;
factorial(col):阶乘;
ceil/floor/rint(col):近似;
round/bround(col[,scale]):HALF_UP/HALF_EVEN rounding mode,整数scale控制近似精度,负数表示整数部分精度。
degrees/radians(col):弧度和角度转换;
cos/sin/tan/acos/asin/atan(col)/atan2(y,x):三角/反三角函数;
sinh/cosh/tanh/acosh/asinh/atanh:双曲/反双曲函数;
bitwise_not(col):
shiftleft/shiftright/shiftrightunsigned(col,numBits)
exists(col,f):返回指定判断函数的真值;
hypot(x,y):sqrt(a^2+b^2)
数值特征处理
MinMaxScaler:$(0,1)$规范化;
字符串计算函数
length(col):字符串或字节序列的长度;
levenshtein(left, right):两个字符串的Levenshtein距离;
sentences(string,language=None,country=None):将字符串拆分为语句数组,语句拆分为单词数组。
字符串变换
initcap/lower/upper(col):
translate(srcCol,matching,replace):对srcCol出现在matching中的字符替换为replace相应位置上的字符,例如matching='123',replace='ZYX',则替换规则为1->Z,2->Y,3->X;
ascii(col):计算字符串的首字符ASCII码数值;
lpad/rpad(col,len,pad)
trim/ltrim/rtrim(col)
repeat(col, n):复制字符串n次构成新值;
reverse(col):反转字符串(或数组);
split(str,pattern,limit[3.0]):按指定模式(Java正则表达式)拆分字符串;
查找替换
instr(col,substr)/locate(substr,col,pos=0):查找子串;
substring(col,pos,len):获取子串;substring_index(str,delim,count)查找分隔符出现count次之前的子串(如果count为负数则反向查找)。
overlay(src,replace,pos,len=-1):从src的指定位置pos(位置从1开始),用replace的内容替换src内容,最大替换长度为len;
regexp_extract(str, pattern, idx):抽取idx指定的捕获组,如果模式未匹配或指定捕获组未匹配,返回空字符串。
regexp_replace(str, pattern, replacement)
编码
base64/unbase64(col):BASE64编码/解码;
crc32(col):计算二进制序列的CRC32校验值返回bigint;
hash/xxhash64(*col):计算输入列元素的HASH整数值/长整数值;
md5/sha1(col)/sha2(col,numBits):返回输入列的MD5/SHA-1/SHA-2xx十六进制编码字符串;
bin(col):二进制数据的字符串表示;
hex/unhex(col):字符串/整数的十六进制字符串表示(字符串每个字符的ASCII码值映射为十六进制);
conv(col,fromBase,toBase):字符串表示的数值进行进制转换;
decode/encode(col,charset)使用指定编码方法将字节序列解码为字符串(将字符串编码为字节序列);
concat(*cols)/concat_ws(sep,*cols):将多个列字符串/字节序列拼接为新数据;
format_string(format, *cols):printf模式输出新列;
日期计算函数
year/quarter/month/hour/minute/second(col)
add_months(start,months)/date_add/date_sub(start,days)
next_day(date, dayOfWeek):返回下一个是指定DayOfWeek的日期(“Mon”, “Tue”, “Wed”, “Thu”, “Fri”, “Sat”, “Sun”)
trunc(col_date,format)/date_trunc(format,col_timestamp):按给定格式舍弃末尾的时间值;timestamp_seconds(col):[3.1]截取时间字段到秒;
datediff(end,start):返回两个日期间相差的天数;months_between(date1,date2[,roundOff])计算两个日期间相差的月数(如果为月中同一天或最后一天返回整数,否则返回浮点数);
dayofmonth/dayofweek/dayofyear/weekofyear/last_day(col):last_day表示日期所在月的最后一天;
date_format/to_date(col,format):将date/timestamp/string类型的日期按给定格式(形如yyyy-mm-dd)转换为字符串。to_date->col.cast("date")。
from_unixtime/to_timestamp/unix_timestamp(col,format=None):将时间戳(秒)转换为时间文本(to_timestamp->col.cast("timestamp"),unix_timestamp输入列如果为指定则返回当前时间);
from_utc_timestamp/to_utc_timestamp(timestamp, tz):可指定时区。
排序
asc/asc_nulls_first/asc_nulls_last/desc/desc_nulls_first/desc_nulls_last(col):返回排序表达式。
df.orderBy(*cols)/df.sort(*cols,ascending=True):使用上述UDF声明排序表达式。
df.sortWithinPartitions(*cols,ascending=True)
集合类型处理函数
数组计算
array(*cols)/array_repeat(col,count):将一个或多个列拼接成数组、将一列重复构成数组;
array_join(col,delimiter[,null_replacement]):将数组拼接为字符串;
zip_with(left,right,f(l,r)):合并两个序列,合并值基于两个序列相应元素通过f计算;
flatten(col):拼接嵌套数组(指拼接第一层嵌套);
array_contains(col, value)
forall(col,f):判断数组元素是否都满足判断条件f;
transform(col,f):[3.1]对数组每个元素进行f变换,返回变换后的数组;
element_at(col,idx):从数值提取指定索引的元素;
slice(x,start,length):返回子数组;
array_max/array_min(col)/array_position(col,value):查找元素;
array_sort(col)/sort_array(col,asc=True):(升序)排序;
array_remove(col,element)/array_distinct(col):移除指定元素;去除重复元素;
array_except/array_intersect/array_union(col1,col2):集合操作(差集/交集/并集);
arrays_overlap(a1,a2):判断两个数组是否存在公共元素(如果无公共元素且都包含null返回null)。
shuffle(col):随机置换序列元素。
字典计算
create_map(*cols):使用输入列构建字典,输入列分别轮流作为字典的key和value值;
map_concat(*cols):将多个输入的字典拼接为一个字典;
map_from_arrays(col1, col2):将两列数据分别转换为字典的key和value,如果输入数据为数组,则返回的字典包含多个字段;
map_zip_with(col1,col2,f(key,v1,v2)):[3.1]合并两列字典,使用指定函数合并相同key对应的value;
map_entries[3.0]/map_keys/map_values(col)<->map_from_entries(col):将字典的key和value转换为一条记录Row(key=,value=),并将所有记录拼接为数组返回(后续可通过explode将数组中的记录展开为数据表中的记录)。
transform_keys/transform_values(col,f):对字段的key/value执行f变换、返回变换后的字典;
map_filter(col, f(k,v)):[3.1]过滤字典中不满足条件的字段;
结构体计算
struct(*cols):基于列名和列类型生成StructType;
结构化数据处理
CSV文本处理[3.0]
from_csv(col,schema[,options]):将CSV字符串转换为一行记录;
to_csv(col[, options]):将StructType转换为CSV字符串;
schema_of_csv(col,options=None):从CSV字符串推测Schema;
JSON文本处理
from_json(col,schema,options=None):将JSON文本转换为Row/StructType对象(可再从结构体扩展为多列);使用schema_of_json(json:str,options[3.0])从==JSON文本==推测Schema并传递给from_json;
get_json_object(col,path):使用JSON Path从==JSON文本==提取字段,例如"$.field";
json_tuple(col,*fields):从==JSON文本==的根节点提取一个或多个字段fields;==由于get_json_object和json_tuple没有指定Schema,返回数据转换为字符串(默认类型)==。
to_json(col,options=None)将StructType、ArrayType或MapType转换为JSON文本;
按元素变换
df.replace(to_replace[, value, subset])
过滤
行过滤
filter(col,f):行过滤;
df.filter/where(col_expr):数据集过滤;df.toDF(*cols)基于列名过滤;
df.limit(num)->DataFrame:保留num行数据;
df.sample([withReplacement, …])
df.dropna(how='any',thresh=None,subset=None):how=any|all,thresh指定null的比例,subset指定检查的列;
df.distinct()/df.drop_duplicates([subset]):保留唯一行。
列过滤
df.select(*cols)或df.select(df.columns[i:j]):按列名或列编号选择列;
df.drop(*cols)或df.drop(df.columns[i:j]):按列名或列编号丢弃列;
df.colRegex(colNamePattern)->Column:选择列名与模式匹配的列;
插入和扩展
插入新列
df.withColumn(colName, col):添加或替换一列数据;添加的数据列仅能为常量或基于当前DataFrame声明的列变换(从而保存分布式数据结构计算的兼容性)。
将集合类型扩展为多列
将字典或序列转换为多列
使用列的getItem()函数可按位置或键名获取集合类型的元素,从而实现一列到多列的变换。由于字典或序列长度可能不统一,导致无法合并并行处理结果,必须预先给定固定数量的列或列名。
col_names = ['a', 'b', 'c']
cols = [df['map_col'].getItem(col).alias(col) for col in col_names]
cols = [df['list_col'].getItem(i).alias(str(i)) for i,_ in enumerate(col_names)]
df_new = df.select(*cols)
如果实际已知MapType具有固定数量且相同的字段,则可以:
col_names = list(df.first().asDict()[col_name].keys())
将结构体转换为多列
由于结构体具有固定字段,所以能够并行处理:
df.select("struct_col.*")
df.select([df['struct_col'].getField(f) for in fields])
将集合类型扩展为多行
explode/explode_outer/posexplode/posexplode_outer():将输入列(序列/字典)扩展为多行记录;其中字典的key和value分别映射为两列(后者保留null元素)。pos-函数为返回值增加位置编号字段(表示其在源数据中的顺序,默认为pos)。
数据集运算
df.join(other[, on, how])
df.crossJoin(other)
df.exceptAll(other):数据集列差集,返回在当前数据集但不在另一个数据集的列;
df.intersect/intersectAll(other):返回两个数据集都存在的行(intersectAll保留重复);
df.subtract(other):返回在此数据集但不在另一个数据集的行。
df.union/unionAll(other):==纵向拼接==(不去重,使用df.distinct()去重);
df.unionByName(other, allowMissingColumns=False):根据列名对应拼接;
聚合
聚合内置函数:aggregate(col, initialValue, merge[, finish])
df.agg(count_distinct(df.age, df.name).alias('c'))
分组聚合:df.groupBy(col:Column,...).agg_func()
agg(*expr)
apply(udf)
applyInPandas(func, schema)
# avg/count/max/min/mean/sum... => 存在等效的UDF
时间窗口聚合:
w = df.groupBy(window("date", "5 seconds")).agg(sum("val").alias("sum"))
col.over(window)
统计量
avg/count/max/min/mean/sum(col):
stddev/stddev_samp/stddev_pop(col):样本/总体标准差(stddev->stddev_samp);
variance/var_samp/var_pop(col):样本/总体方差=>df.cov(col1,col2);
corr/covar_pop/covar_samp(col1,col2):计算两列的相关系数/总体协方差/样本协方差;=>df.corr(col1,col2[,method])
approx_count_distinct(col[, rsd]):近似统计列的不同值数量。
count_distinct/sum_distinct(*cols):统计不相同元素的数量/求和;
累积数值运算
product(col):累计运算;
合并拼接
collect_list/collect_set(col):将列数据合并为序列或集合;
采样
first/last(col[,ignorenulls]):获取分组的第一个元素;
窗口操作
lag/lead(col[,offset,default]):返回当前行的前/后第offset行的值;
nth_value(col, offset[, ignoreNulls]):返回当前窗口中第offset行(从1开始)的值;
输出
在Driver侧输出DataFrame的数据信息:
df.printSchema()
df.explain() # Prints the (logical and physical) plans
df.count()
df.show(vertical=False)
在Driver侧收集DataFrame数据:
df.collect() # -> List[Row]
df.take(num) # -> List[Row]
df.head/tail(n=NUM) # -> List[Row]
df.first() # -> Row <=> df.head()
df.toPandas() # -> pandas.DataFrame
df.to_pandas_on_spark([index_col])
注意,上述方法与
df.limit()不同,后者输出未SparkDataFrame。
df.foreach(f(Row))
df.foreachPartition(f(List[Row]))
df.toLocalIterator(prefetchPartitions=False):将每个分区逐次取到本地进行处理;
for part in df.toLocalIterator(prefetchPartitions=False):
# do processing in client
# part is a Local DataFrame
存储方法
writer=df.write->DataFrameWriter:
writer.format(<source>):输出格式包括:csv,json,jdbc,parquet,...,等效调用writer.<source>;
df.writeStream
CSV存储参数
- 存储方法
- 模式
mode='append'|'overwrite'|'ignore'|'error'; - 压缩
compression=None|'bzip2'|'gzip'|'lz4'|'snappy'|'deflate':CSV读取不止解压缩方法,因此如果还要将存储数据读出来则选择不压缩输出。
- 模式
- 数据格式:
header=False:将数据的字段名写入文件的首行;
- 特殊字符,参考CSV读取参数;
escapeQuotes=True:默认将包含引号的字段使用引号包围并对其中的引号转义;quoteAll=False:将所有字段使用引号包含;
- 数值格式,参考CSV读取参数;
分区
df.repartition(numPartitions, *cols)
writer.partitionedBy(days("ts"))
分区方法
years/months/days/hours(col):按天分区;
Spark SQL Guide: Getting Started - Spark 3.2.0 Documentation (apache.org)
Spark SQL API Reference — PySpark 3.2.0 documentation (apache.org)
用于从Hive读取数据生成DataFrame或DataSet。
Spark Pandas API
Pandas DataFrame [3.2]
Spark SQL and DataFrames - Spark 3.2.0 Documentation (apache.org)
Quickstart: Pandas API on Spark — PySpark 3.2.0 documentation (apache.org)
Pandas API on Spark User Guide — PySpark 3.2.0 documentation (apache.org)
Pandas API on Spark Reference — PySpark 3.2.0 documentation (apache.org)
Spark Streaming
可扩展、高吞吐、可容错的实时数据流处理。

内部数据流
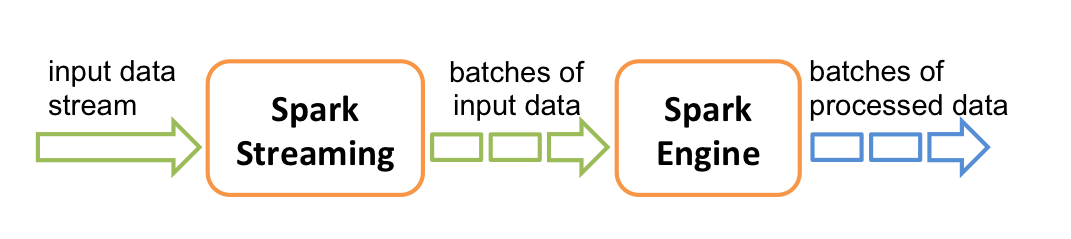
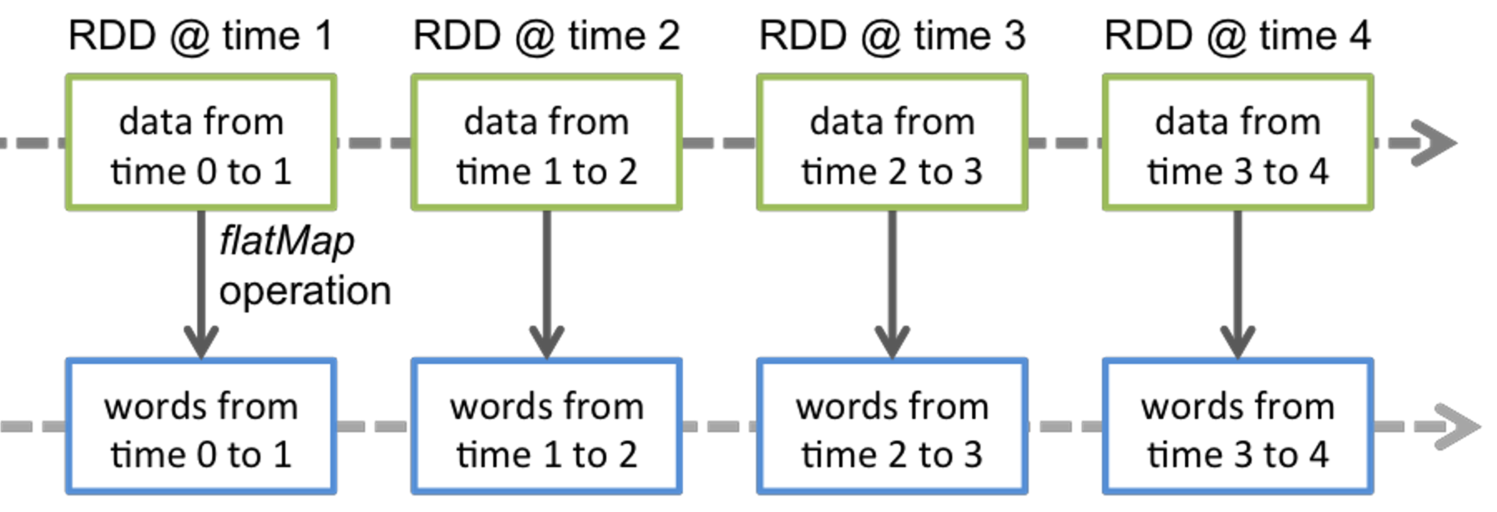
将数据流拆分为小批次(discretized stream or DStream,a sequence of RDDs)。每一次处理程序调用时,接收到的数据在Spark上生成一个RDD对象。
数据源:kafka、TCP socket、……
算法API:map、reduce、join、window;可将机器学习算法和图处理算法应用于数据流;
输出:文件、数据库、仪表板
流处理程序框架
以Kafka作为数据源的流处理程序框架:
sc = SparkContext(conf=conf) # 创建Spark连接上下文
stream_context = StreamingContext(sc, batchDuration=5) # 创建Kafka流处理上下文
# 设置Kafka消费者订阅参数
zookeeper = 'node1:2181,node2:2181,node3:2181'
group_id = 'spark-streaming-consumer'
topics = {'noah.unix': 1}
# 创建Kafka数据流: 需要根据数据源的编码格式指定对应的解码方法
kafkaStream = KafkaUtils.createStream(
stream_context, zookeeper, group_id, topics,valueDecoder=msgpack.loads)
# 流处理过程:KafkaDStream/TransformedDStream变换方法
results = kafkaStream.map(func1).reduce(func2)...
# 输出过程
kafkaStream.foreachRDD(proc_rdd) # 定义每一批数据的处理函数
stream_context.start() # 启动流处理任务
stream_context.awaitTermination() # 等待流处理结束或中断,防止程序提前退出
在上述框架中添加的普通Python程序(例如打印语句)仅会被执行一次,只有流处理相关代码才会在流数据处理每次触发执行时被执行。当流处理启动后,不能再修改处理过程。程序同一时间仅能有一个有效的
StreamingContext,一个StreamingContext可以创建多个数据流。
数据源
stream_context.socketTextStream("localhost", 9999) # TCP socket数据源
stream_context.textFileStream(dataDirectory) # python仅支持文本文件(HDFS)
Kafka连接模式
Reciever模式
上述框架采用Reciever模式。Receiver接收的数据储存在Spark执行器中,Spark流处理任务处理接收的数据。如果任务出错可能导致数据丢失,需要启用Write Ahead Logs将接收数据写到分布式存储以在必要时恢复。
Receiver要占用Spark应用的一个任务线程,因此分配给执行器的
cores总数要大于1。
直连模式
kafkaStream = KafkaUtils.createDirectStream(
kafka_context, list(topics.keys()),
{"metadata.broker.list": "node1:9092,node2:9092,node3:9092"},
valueDecoder=msgpack.loads
)
流处理过程
处理过程以RDD作为处理对象,针对当前批次数据RDD执行map、reduce等分布式变换处理操作,返回TransformedDStream处理结果。
流处理过程是在执行器上分布式执行的,因此在Driver侧无法查看这些处理过程中的输出。
map(func):对当前批次数据的每一条记录执行运算并返回结果;传递给func的数据为RDD中每一条记录(普通Python对象)。
mapPartitions(func):对当前批次数据的每个分片执行map操作,传递给func的数据是一个分片。该变换的效果和map相同,返回结果都是包含每条记录的RDD。使用该方法代替map()的场景为减少变换方法需要反复执行的初始化操作。
因为无法通过数据序列化将特殊对象从Driver传递给执行器(例如数据库连接),因此需要在变换方法中反复调用初始化方法,造成较大开销。利用
mapPartitions仅需为每个分片在对应的执行器上执行一次初始化。
def func_partition_map(data:Iterable):
for data in Iterable:
yield func_map(data)
flatMap(split_func):一对多映射,将一条记录拆分为序列,并将其转换为多条记录。
transform(trans_func):将一批数据RDD整体进行变换,可定义任意针对RDD的变换方法。可以在trans_func中将RDD转换为DataFrame。
filter(func):仅返回func值为true的记录。
统计聚合
count()->TransformedDStream:返回当前批次数据的数量(标量RDD)。
countByValue():统计不同记录的数量(groupby-count),返回包含(record, num)的数据流。
reduce(redfunc):对当前批次数据执行reduce运算,并返回标量RDD。redfunc应该满足结合律和交换律从而支持并行计算。
reduceByKey(func, numPartitions=None):(groupby-aggregate)对于数据结构为(key,value)的数据流,按key分组,并对value进行聚合。numPartitions指定分组任务的并行数量(即RDD的分片数量,集群模式默认值为spark.default.parallelism)。
updateStateByKey(func_update_state):数据记录内部状态维护。对于数据(key,value),针对每个key维护一个状态变量(可定义任意数据类型)。当处理一批数据时,会将每个key对应的值构成序列传递给状态更新函数,基于该值序列可计算更新状态。
def func_update_state(values, state):
if state is None:
# init_state
# state_update <- values
# state <- state + state_update
return state
时间窗操作
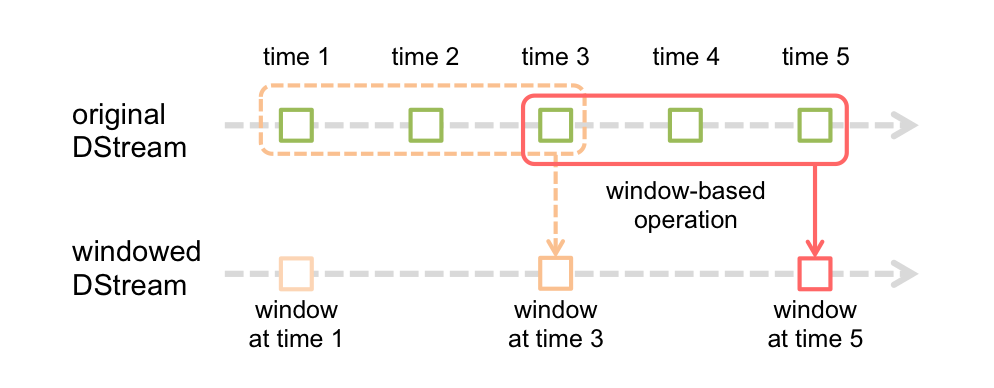
窗口操作时间参数:1)windowDuration:时间窗长度;2)slideDuration:滑动时长;均为处理周期的整数倍。
window(...) :获取时间窗口中的所有数据。
countByWindow(...):获取时间窗口中的所有数据的计数。
reduceByKeyAndWindow(func,[invFunc],...,numPartitions=None,filterFunc=None):记录滑动窗口中每个批次数据的聚合结果reduceByKey,通过func将新加入窗口的批量数据的聚合结果合并到窗口聚合结果中,利用invFunc从窗口聚合结果中移除离开活动窗口的批量数据的聚合结果。如果未提供invFunc(某些合并结果可能也不支持反向移除),那么每次要对聚合窗口中的每个批次的聚合结果做合并,因此效率较低。filterFunc基于数据(key,value)进行过滤,仅对满足条件的数据聚合。
countByValueAndWindow()基于countByValue结果;reduceByWindow()基于reduce结果。
内部变换
repartition(numPartitions):将RDD重新分片。
多数据流处理
union(otherStream):和其他数据流合并。
join(otherStream,numPartitions=None):合并数据流,(K,V)+(K,W)->(K,(V,W));还可以指定合并方式:leftOuterJoin,rightOuterJoin,fullOuterJoin。
cogroup(otherStream,numPartitions=None):合并数据流,将每个数据流相同键值的数据聚合为一个序列再进行拼接,(K,V1)+(K,V2)...+(K,W1)+(K,W2)+...->(K,(V1,V2,...),(W1,W2,...))。
输出过程
针对当前批次数据执行输出操作(标准输出、文件、数据库、流引擎……),无返回数据。==流处理流程需要以输出过程来触发处理过程执行,否则系统会直接丢弃数据而不会执行变换处理操作==。
pprint: (num=10):输出当前批次数据RDD中前num条记录;如果RDD为序列类型则输出为序列,如果为标量,则输出标量。
saveAsTextFiles(prefix, [suffix]):输出文件名称格式prefix-TIME_IN_MS[.suffix](PythonAPI仅支持文本文件)。
foreachRDD(proc_rdd):对当前批次数据进行自定义处理。可在处理逻辑中添加输出方法。proc_rdd是==运行在Driver侧==的方法(不要将连接对象传递给执行器),因此可以将数据输出到终端、保存到Driver节点的文件系统、输出到数据库或HDFS。也可将RDD转换为DataFrame再执行输出处理。
def proc_rdd(data: RDD):
data = rdd.map(...).reduce(...) # 进一步分布式操作
print(data) # 输出到driver终端
pd.DataFrame.from_records(data).to_parquet(FILEPATH) # 输出到文件
Checkpointing容错机制
How to configure Checkpointing
性能优化
Structured Streaming
结构化流处理是基于Spark SQL引擎的可扩展、高容错流处理引擎。可以使用Dataset/DataFrame API来描述数据处理过程。
容错机制:checkpointing and Write-Ahead Logs。
处理模式:
- micro-batch processing:最少延迟100ms(默认);
- continuous processing:最少1ms延迟(Spark 2.3+)。
流处理程序框架
stream_df = spark\
.readStream\
.format("kafka")\
.trigger(processingTime=None,...)\ # 流处理周期
.option("kafka.bootstrap.servers", "node1:9092,node2:9092,node3:9092")\
.option("subscribe", "tpoics")\
.load()
# "topic1,topic2" | "topic.*"
query = stream_df.select(...)\
.writeStream.foreachBatch(batch_func)\
.start()
query.awaitTermination()
流处理程序必须以流式DataFrame进程传递,最后调用writeStream进行输出。
变换过程必须返回流式
DataFrame,否则产生*Queries with streaming sources must be executed with writeStream.start();*
流处理周期
可设置一项触发选项,指定处理周期。
reader.trigger(processingTime='5 seconds',once=None,continuous='1 minute')
Structured Streaming Programming Guide - Spark 3.2.0 Documentation (apache.org)
Structured Streaming API Reference — PySpark 3.2.0 documentation (apache.org)
输入
可使用与批量处理相同的接口读取文件,此外还可指定流数据源(如Kafka)。
Kafka输入流数据可能是以字节序列存储,需要在接收数据后自行进行反序列化(解码)。
变换处理
由于数据流以结构化的流式DataFrame组织,因此Spark SQL的DataFrame API都适用于流数据的处理。
Kafka数据流除了数据字段
value,还包含元数据字段,包括key,topic,partition,offset,timestamp,timestampType,headers。实际处理开始前,需要首先从value字段(例如JSON文本)中将数据字段提取出来并结构化为新的DataFrame。
输出
writer.outputMode('append|complete|update'):
writer.queryName('streaming_query'):指定处理流程的名称(query.name);
外部存储
参考批量处理的输出方式,仅支持append模式。
输出至Kafka
自定义处理
foreach
def proc_row(row):
# ......
class ForeachWriter:
def open(self, partition_id, epoch_id): # 创建到目标的writer连接
def process(self, row): # 处理和写入数据
def close(self, error): # 关闭writer连接
df_stream = writeStream.foreach(proc_row).start() # Append,Update,Complete
foreachBatch
def batch_print(df: DataFrame, epoch_id: int):
print(f"_________________ {epoch_id} ____________________")
df.persist() # 防止重复计算
df.printSchema()
df.show()
df_stream = writeStream.foreachBatch(batch_func).start() # Append,Update,Complete
不支持连续模式,使用
foreach。
调试输出
console
writeStream.format('console')\
.option('numRows', 20)\
.option('truncate', True)\
.start() # Append,Update,Complete
memory
writeStream.format("memory").queryName("tableName").start() # Append,Complete
图分析算法
GraphFrame
GraphFrame库用于在Spark上基于DataFrame表示图数据,并封装了图分析算法。
conda create -n graph -c conda-forge pyspark graphframes
在代码中引用GraphFrame库:
from graphframes import *
spark = SparkSession.builder\
.appName('Spark Graph')\
.config('spark.jars.packages', 'graphframes:graphframes:0.8.1-spark3.0-s_2.12')\
.getOrCreate()
或通过命令行(spark-submit或pyspark)参数添加引用:
pyspark --packages graphframes:graphframes:0.7.0-spark2.4-s_2.11 #*
*:根据实际安装的Spark版本,从Maven仓库选择对应版本的库。
通过分别表示图的节点和边的DataFrame构造图对象,通过edges和vertices访问图的边和节点。
g = GraphFrame(v, e)
g.vertices
.filter("population > 100000 and population < 300000")
.sort("population")
图分析算法
from_expr = "id='Den Haag'"
to_expr = "population > 100000 and population < 300000 and id <> 'Den Haag'"
result = g.bfs(from_expr, to_expr)
GraphX
MLlib
MLlib: Main Guide - Spark 3.2.0 Documentation (apache.org)
MLlib (DataFrame-based) API Reference — PySpark 3.2.0 documentation (apache.org)
Breeze, which depends on netlib-java
native BLAS such as Intel MKL, OpenBLAS, can use multiple threads in a single operation, which can conflict with Spark’s execution model.